I’ve been looking over everyone’s content on this topic and I’ve found it all to be lacking for one reason or another. So I’ll post a complete overview here. What’s especially been missing is historical perspective and why certain things exist the way they do.
Back in 1962, teletype was quite common. These systems worked by sending binary signals over a physical wire. So a machine on one end could send bits (binary digits) to another machine on the other end. Well, if we group bits together, we basically have ourselves a base-2 numbering system. And because of this, we can represent arbitrary integer values. The more bits we assign to each value, the higher the maximum value we can represent.
In order for meaningful messages to be conveyed, a standardized encoding system had to be devised. Such schemes are called code pages. Their purpose is to map linguistic symbols (or parts of symbols) to numerical values called code points. Each symbol has its own code point and each code point is unique to that symbol.
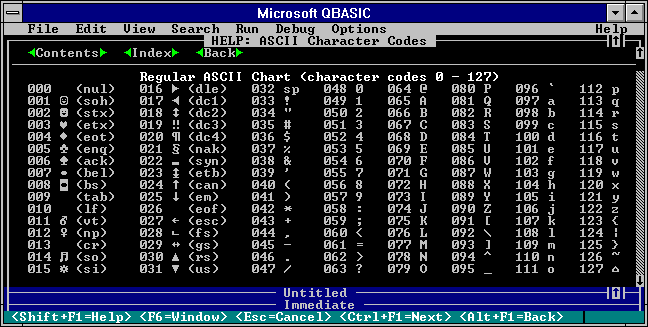
For the purposes of teletype, a 7-bit system called ASCII was devised. It is shown below:
This is the system that the United States used for teletype and it became widely adopted as an industry standard.
Sometime in the 1970s, personal computers started to become a thing. And like teletype systems, they also needed to be able to represent linguistic symbols using binary code. Except computers are a bit different from teletype: Whereas teletype doesn’t care about how many bits are assigned to a symbol, computers like to have everything be accessible in even powers two. ASCII was a logical choice for computers, but it was a 7-bit system. Seven is not a power of two, but eight is. Eight bits became commonly known as a byte and each ASCII value was represented with a single byte, except the first bit was typically set to zero (since it wasn’t needed).
Well, this gives us a whole extra bit to work with. Meaning, we have ASCII from 1962 with bit patterns of 0XXXXXXX (Regular ASCII), but we can also define a whole different code page with bit patterns of 1XXXXXXX (Extended ASCII).
The most common Extended ASCII code page that I remember is called CP437:
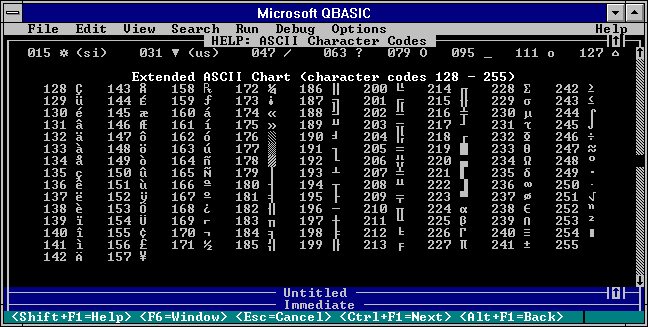
And so Regular ASCII code point values range from 0-127 while Extended ASCII ranges from 128-255.
The United States may have adopted CP437 as its Extended ASCII code page, but other regions of the world had little use for it. What they did have use for, however, was repurposing the Extended ASCII range to contain their own localized linguistic symbols. Well, here’s the problem. All files really contain is bytes of data, and computers only know to display that data according to the code page they’re configured for. Computers back then didn’t know or care about which code page a file was really encoded in, they would simply display it as they knew how. Imagine opening a Russian file on a machine configured for Israel’s code page. You’ll see Hebrew, but it will be absolute gibberish. And for that matter, if you find a text file, how do you even know what code page it’s encoded with?
Well this system of different, incompatible code pages may have been fine for data staying within a region, but it made international document exchange extremely tedious. What the industry wanted was a single code page that contained any linguistic symbol anyone could possibly want to show.
And so the industry created Unicode 1.0 and released it in October of 1991. It defined a code page of 65,536 code points now known as the Basic Multilingual Plane, or BMP for short. Now pay attention to this next part because it’s extremely important: The BMP extended the original 7-bit ASCII code page. That means the code point values for English letters, numbers, and symbols all stayed the same between Regular ASCII and the new Unicode system. Therefore, any BMP code points between 0 and 127 inherently refer to Regular ASCII. But that is where the similarities end.
Addressing 65,536 unique code points was accomplished by using two bytes instead of one. When it came to Regular ASCII (which only needed one byte), each one was preceded by a null byte. So while a single byte of 0x20 represents a space in Regular ASCII, two bytes of 0x00 and 0x20 are used to do so here. This encoding scheme was called UCS-2.
Now pay attention again, because this next part is also critically important: UCS-2 could not safely pass through most text buffers at the time. Remember that UCS-2 encodes Regular ASCII code points by prepending a null byte. Well, most text buffers assume a null byte to mark the end of the text sequence. ASCII sequences would have them deliberately inserted for this purpose only, but UCS-2 did it for every character in the English language. In other words, your English text would terminate before it even began.
Despite this glaring shortcoming, Windows NT, Mac OS, Java, and JavaScript all jumped on the UCS-2 bandwagon. Their text handling runtimes were renovated to internally use it. And this was fine for them because their buffers didn’t terminate due to the presence of a single null byte (anymore).
But there was a problem: Almost nobody used Windows NT, Mac OS, Java, or JavaScript; so almost nobody could handle UCS-2. And given that MS-DOS, Windows 3.x, and Windows 9x couldn’t even transport it because of the null byte issue, there was really no integration path forward for handling Unicode on these predominant systems.
And to top things off, people were realizing that a code page with 65,536 entries simply wasn’t going to be enough.
The Unicode Consortium went back to the drawing board. They had three major issues to solve:
The Unicode code page was ultimately extended by appending sixteen supplemental planes to the existing Basic Multilingual Plane. This kept the code point values for the BMP the same as before, but added new ones after it for the sixteen other planes. Each supplemental plane, like the BMP, contains 65,536 code points.
With the Unicode 2.0 code page massively expanded, UCS-2 needed to be extended to address these additional planes. While simply tossing it and redefining a more concise replacement would have been desired, it was ultimately infeasible. Microsoft had already begun moving internally to make all new versions of Windows based on NT. Meanwhile, Java and JavaScript had already begun to see an uptick in popularity. Unfortunately, UCS-2 was here to stay. But fortunately, there was an extension path forward.
Unicode 1.0 didn’t define characters for all 65,536 code points within the BMP. It left a large chunk of them open for future use. Part of this available segment was taken and split into two different ranges called surrogates. One subrange was the high surrogates and the other was the low surrogates. A single high surrogate and a single low surrogate could then be combined to form a surrogate pair in order to address a supplemental character. So while UCS-2 considered a surrogate pair to be two separate BMP characters, this new UTF-16 scheme saw each one as a single supplemental character. Windows NT, Mac OS, Java, and JavaScript were all updated from UCS-2 to UTF-16, thereby allowing them to understand surrogate pairs and the supplemental characters they represent.
Therefore, all UCS-2 that is within the defined Unicode 1.0 code page is inherently valid UTF-16. And UTF-16 can be safely stored by legacy UCS-2 systems so long as those systems do not truncate or cut text. This is, again, because UCS-2 is not surrogate-aware and will happily separate a compound pair.
UTF-16 is the native encoding scheme for Unicode 2.0 and later, and Unicode’s current limit of 1,112,064 unique code points stems from the number of unique values that UTF-16 can address with its basic (UCS-2) and surrogate pair systems combined.
And so getting the UCS-2 operating systems and runtimes extended to handle the larger Unicode 2.0+ code page was taken care of, but what about systems that couldn’t handle null bytes?
Before I get into this, I have to say that UTF-8 is easily one of the top five most ingenious inventions in computer science. The engineer who created it, Ken Thompson, did so on the back of a napkin in a diner. He also deserves a Nobel Prize. I’ll tell you why...
UTF-8 encodes all possible code points, both BMP and supplemental, using anywhere from one to four bytes. Now remember up above where I said that the Unicode code page extended the Regular ASCII code page? Well, UTF-8 encodes these values as single bytes. Not only that, but as single bytes that are identical to their Regular ASCII counterparts. This means that UTF-8 containing only Regular ASCII is itself Regular ASCII. And, any Regular ASCII text can be natively interpreted by UTF-8 as-is.
Anything outside of that Regular ASCII range requires two to four bytes. Here are the possible bit patterns that UTF-8 currently uses:
0XXXXXXX110XXXXX 10XXXXXX1110XXXX 10XXXXXX 10XXXXXX11110XXX 10XXXXXX 10XXXXXX 10XXXXXXThe X placeholders are where arbitrary bits for code point values are stored. Any UTF-8 sequence whose byte starts with a zero bit is Regular ASCII and is therefore encoded as such; legacy systems already display these properly. Meanwhile, code points outside of this range appear to legacy systems as a sequence of Extended ASCII characters; legacy systems may not display them properly, but they will not cause problems, either. Null bytes are never encountered unless specifically intended.
Note that the four byte sequences are used for encoding supplemental characters directly as opposed to using the surrogate mechanism from UTF-16. It is against specification to encode a surrogate itself with UTF-8.
Another useful aspect of UTF-8 is its self-synchronization feature. This makes it possible to skip to the middle of a UTF-8 byte stream and determine what role in a character the current byte plays:
0XXXXXXX: A complete Regular ASCII character.10XXXXXX: A continuation byte of a multi-byte character.110XXXXX: The first byte of a two-byte character.1110XXXX: The first byte of a three-byte character.11110XXX: The first byte of a four-byte character.111110XX: The first byte of a five-byte character (not valid Unicode).1111110X: The first byte of a six-byte character (not valid Unicode).11111110: Invalid byte.11111111: Invalid byte.Being ASCII-compatible in this manner allowed UTF-8 to be treated as the single drop-in replacement for all region-specific code pages. Effectively, UTF-8 bridged the gap between the prevalent world of ASCII and the new world of Unicode. Unicode’s prominence today is owed entirely to this bridge.
Since the release of the Unicode 2.0 specification, real-world use of official encodings has become something other than what was intended. And new, unofficial encodings have emerged to permit Unicode to be used in certain niche scenarios. Of everything listed below, only UTF-8, UTF-16, and UTF-32 are officially a part of that specification.
| Name | Bytes | Supplemental Characters | ASCII Compatible |
|---|---|---|---|
| UTF-7 | 1-8 | Surrogate Encoding | Yes |
| UTF-8 | 1-4 | Direct Encoding | Yes |
| UTF-16 | 2, 4 | Surrogate Encoding | No |
| UTF-32 | 4 | Direct Encoding | No |
| UTF-EBCDIC | 1-5 | Direct Encoding | No |
| GB 18030 | 1, 2, 4 | Direct Encoding | Yes |
| CESU-8 | 1-6 | Surrogate Encoding | Yes |
| WTF-8 | 1-6 | Both | Yes |
Currently defined by RFC 2152, this encoding is not really used anymore. The idea is to encode certain ASCII characters directly while using inline Base-64 for everything else. This inherently does not self-synchronize that well as seeking to the middle of an ASCII string could mean either directly encoded characters or inline Base-64.
It originally found its place in allowing Unicode to pass through 7-bit MIME email. In recent years, mail systems have come to support the 8BITMIME extension, allowing UTF-8 to effortlessly pass through instead.
In recent versions of .NET, The System.Text.Encoding.UTF7Encoding class, while present, results in an exception being thrown. This is due to security issues with the format itself. Browsers that are compliant with HTML5 are required to reject UTF-7 as an encoding.
Originally created as a compatibility mechanism for older operating systems and protocols that used region-specific code pages, UTF-8 has since become the defacto-standard encoding for Unicode. New protocols and formats now typically specify it as the only supported encoding. And older protocols and formats that support configurable code pages now typically see UTF-8 defined with all other encodings coming in a very distant place behind it.
But despite its near universal status, UTF-8 is not as simple to implement as some may suppose. Decoder implementations must take care to exercise proper security practices. Specifically, UTF-8 byte streams may be malformed in the following ways:
0xFE or 0xFF).U+10FFFF or lies in the surrogate range).Despite being the native encoding for Unicode 2.0 and later, UTF-16 is not commonly used anymore in new systems. An argument could be made that UTF-16 bitstreams are cleaner when it comes to processing and validating them. Specifically, UTF-16’s design makes only two types of encoding errors possible:
If the need to interoperate with UCS-2 ever presents itself, UTF-16 becomes the only viable option for doing so. In other cases, it may be desireable to use it internally for enclosed systems, as its representation is arguably cleaner.
UTF-16 can self-synchronize so long as random access is done in two-byte increments.
This encoding is almost never encountered in the wild, although some language runtimes use it internally for string representation. The idea is that any Unicode character in a buffer can be decoded without having to first decode the ones that precede it. While this ability may sound useful at first, it has very limited utility in practice.
It should be noted that the most significant byte is always going to be null, as Unicode itself only requires 21 bits of precision to adequately address all possible characters.
No meaningful commentary is currently offered here, except that EBCDIC platforms typically use UTF-16 for storing Unicode, for some reason.
This is China’s native encoding scheme for Unicode. Its purpose is to store Unicode characters in a manner that is compatible with GBK (1991), which itself is an extension of GB 2312 (1980). Because it is a forwards-compatible extension of these legacy encodings, lookup tables must be used to map between pre-existing GBK code points and Unicode code points. Unicode code points not found in GBK are encoded algorithmically.
The 2000 and 2005 revisions of this encoding utilized Unicode’s Private Use Area to represent characters that were found in GBK, but that were not found in Unicode at the time. With the advent of the 2022 revision, Unicode now contains these missing characters, thereby permitting the 2022 revision to address them in Unicode natively.
Despite requiring lookup tables, it does have the ability to represent Regular ASCII characters with a single byte while still representing common Chinese characters with just two bytes, whereas UTF-8 requires three. It lacks UTF-8’s self-synchronization capability, however, allowing a corrupted GBK sequence to corrupt the rest of the text buffer.
It should be noted that Chinese websites overwhelmingly use UTF-8, including those of the Chinese Communist Party.
This is a modification of UTF-8. The difference is that UTF-8 encodes supplemental characters directly whereas CESU-8 uses surrogate pairs. As such, four-byte sequences never occur in CESU-8.
This is a combination of UTF-8 and CESU-8. Supplemental characters may be directly encoded as four-byte sequences, but they may also appear as a surrogate pair of twin three-byte sequences.